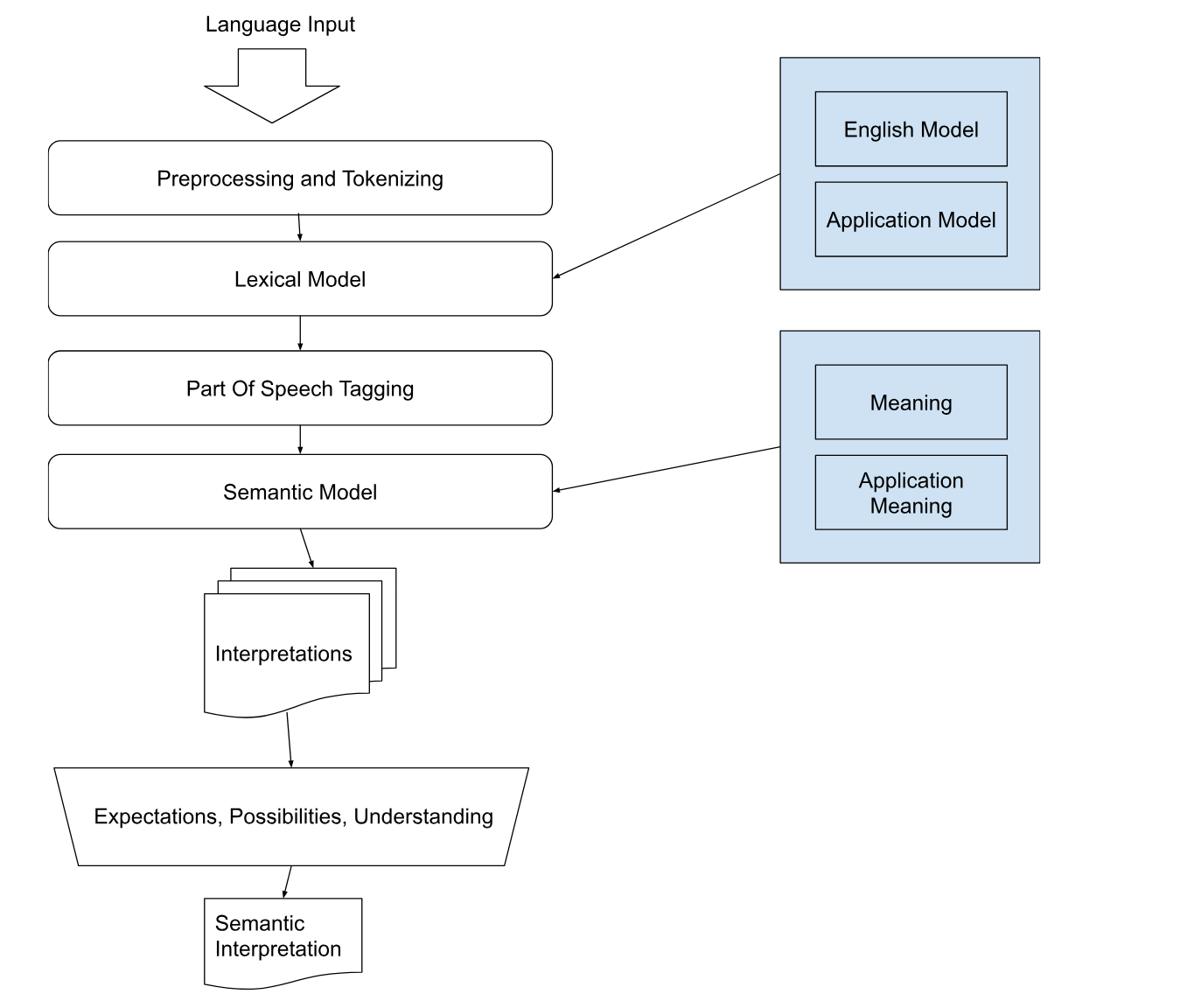
Language Model
The Buffaly Language Model consists of the
- Lexical Model
- Semantic Model
- Part of Speech Model
- Tagger
Lexemes
"a basic lexical unit of a language, consisting of one word or several words, considered as an abstract unit, and applied to a family of words related by form or meaning."
Assume for a minute that any string value that we want to work with is called a lexeme.
- "Buffalo" is a lexeme
- "City" is a lexeme
"Bully" is a lexeme
Sometimes a lexeme is a single word. Sometimes it can span multiple words:
- New York
- United States of America
- Pick Up (the trash)
- Turn Off (the light)
Sometimes a lexeme can contain a interrupting tokens:
- Please [pick] it [up]
- Please [pick] the freaking trash [up]
Sememes
"a semantic language unit of meaning"
For the word "buffalo" we have three "meanings":
- Buffalo (the City)
- Buffalo (the Animal)
- Buffalo (the Action)
Each of these meanings is a semantic unit or sememe. We represent these in ProtoScript as discrete objects
Lexeme to Sememe Mapping
Let's setup the lexeme to sememe mappings for "buffalo" using ProtoScript.
Buffalo (lexeme)
->
Buffalo (the City)
Buffalo (the Animal)
Buffalo (the Action)
We use annotations to map the string value to the various semantic interpretations:
Grammar
Next we let the system know what is possible. In English, we have certain patterns that are available to us.
-
Unary Actions
I eat
She painted
-
Binary Actions
I eat food
She painted the house
-
Ternary Actions
She painted the house red
We also have some rules on how to put different objects together. It is ok to to say
It's not OK to say
Though, in other languages (like Spanish), the adjective comes after the noun.
For our specific example we allow
As in
Or
We don't allow the opposite. The follow sentence sounds strange:
For our example we only need a few patterns.
- City Animal
- Animal Action
- Animal Action Animal
Let's setup those sequences in ProtoScript.
Chomsky Grammars and the Chomsky Hierarchy
The Chomsky hierarchy in the fields of formal language theory, computer science, and linguistics, is a containment hierarchy of classes of formal grammars. A formal grammar describes how to form strings from a language's vocabulary (or alphabet) that are valid according to the language's syntax. Linguist Noam Chomsky theorized that four different classes of formal grammars existed that could generate increasingly complex languages.
This theoretical framework tells us the limits of our approach. On it's own, the sequences
- City Animal
- Animal Action
- Animal Action Animal
are not capable of generating (or parsing) any language -- especially English. But sequences are not constrained by "pattern matching". We can run code, access context, or memory with each sequence match. This gives us the capacity to parse any recursively enumerable language according to Chomsky's theory.
In practice, this approach can parse a wide variety of English language sentences.
Deterministic Tagger
The Deterministic Tagger is a set of components used to turn unstructured text into a graph structures. It uses a reinforcement learning programming approach to build and test valid graphs.
It combines Exploration with Exploitation to find the best options for putting together the pieces of a sentence given known rules.
- It's deterministic. There is no explicit randomness. It will follow the same highest probability path each time it sees the same inputs.
- It learns from experience. Feedback from correct interpretations gets fed back into the system to allow for quicker interpretation next time.
- It is inspectable. We can see why it made a choice at each point in time and adjust the functions that led to that choice
Given a sequence like
Tokenization
Tokenization turns the original string into something more granular. The model is agnostic to the type of tokenizer. We default to word tokenization.
But, the model is able to access sub-word or character level token representations as needed. It can also combine multiple tokens together - even when separated by intermediate tokens.
Hypothesize a sememe
The tagger uses a heuristic and previous training data to pick a starting token (lexeme) and decide which semantic interpretation to use.
Finds the expectations for that sememe
City Animal
- Animal Action
- Animal Action Animal
The first sequence does not fit. The second and third could possibly fit. So it tests
There is indeed a match for this, so it "collapses" the lexeme to a correct interpretation:
At this point, there is only one valid sequence
So we compare again:
There is a way to collapse the lexeme to the correct interpretation: