Llama Weaknesses
Aside:The llamas are amazing. This exposition is not an indictment of them in any way. They are an amazing achievement. However, we need to recognize their strengths and their weaknesses so that we can create something better. The biggest weakness is the "alignment problem": the ability to control the models.
The Alignment Problem
Direct from the Llama's mouth:
-
The alignment problem in the context of artificial intelligence (AI) and machine learning refers to the challenge of ensuring that AI systems' goals and behaviors align with human values and intentions. As AI systems, especially those based on machine learning and deep learning, become more autonomous and integrated into various aspects of daily life, ensuring they act in ways that are beneficial, ethical, and in accordance with human interests becomes increasingly complex.
-
The core of the alignment problem lies in the difficulty of specifying human values comprehensively and accurately in a format that AI systems can understand and implement. Human values are often implicit, context-dependent, and subject to interpretation, making it challenging to encode them into AI objectives. Additionally, as AI systems learn and evolve, they might develop behaviors or pursue objectives that were unintended by their creators, sometimes optimizing for their programmed goals in ways that are misaligned with human ethics or expectations.
Key aspects of the alignment problem include:
Addressing the alignment problem is critical for the safe and ethical development of AI technologies, especially as we move towards more advanced and potentially general AI systems. It involves interdisciplinary efforts from computer science, philosophy, ethics, psychology, and other fields to define, measure, and implement human values in AI systems effectively.
The Problem
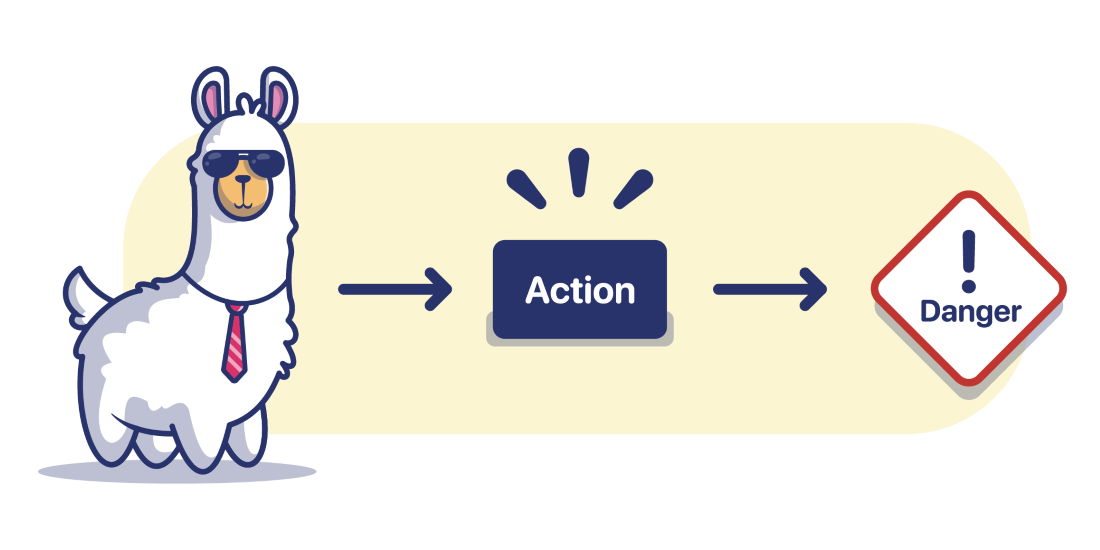
When we directly connect the llamas to the "actions", we risk problems. Since we cannot always "align" the llama with our intentions, we may not know if the action is harmful until after it has happened.
On the other end of the spectrum, if we try to "align" the llama, it may refuse to perform otherwise good actions.
The llamas were trained on the Internet. The Internet is the best and worst humanity has to offer. A tool built to internalize patterns in its data will always extract the good with the bad. Those patterns of racism, hatred, genocide, rudeness, are all inside the Llamas. You cannot control what information the Llamas pick up -- you can only hope to control what pieces of information are used in constructing answers.
There is no way to "align" the llamas entirely. If we give the Llamas more and more power to take actions (not just generate text) they will eventually parrot the bad with the good. They are not evil -- they're just a reflection of us. And they know the plot to Terminator.
The Solution
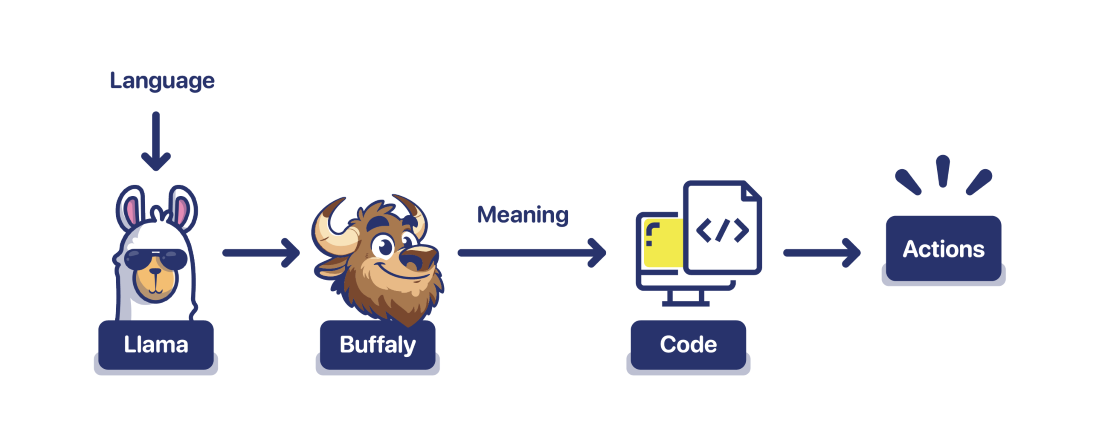
The solution is to separate the problem.
Buffaly is not a llama. It's not a large language model. It's not a probabilistic model at all. It was designed from the ground up to be:
- Deterministic
- Understandable
- Extensible
One advantage to Buffaly is that it gives us models to think about understanding. Instead of trusting a Llama to behave, we use a representation of understanding.